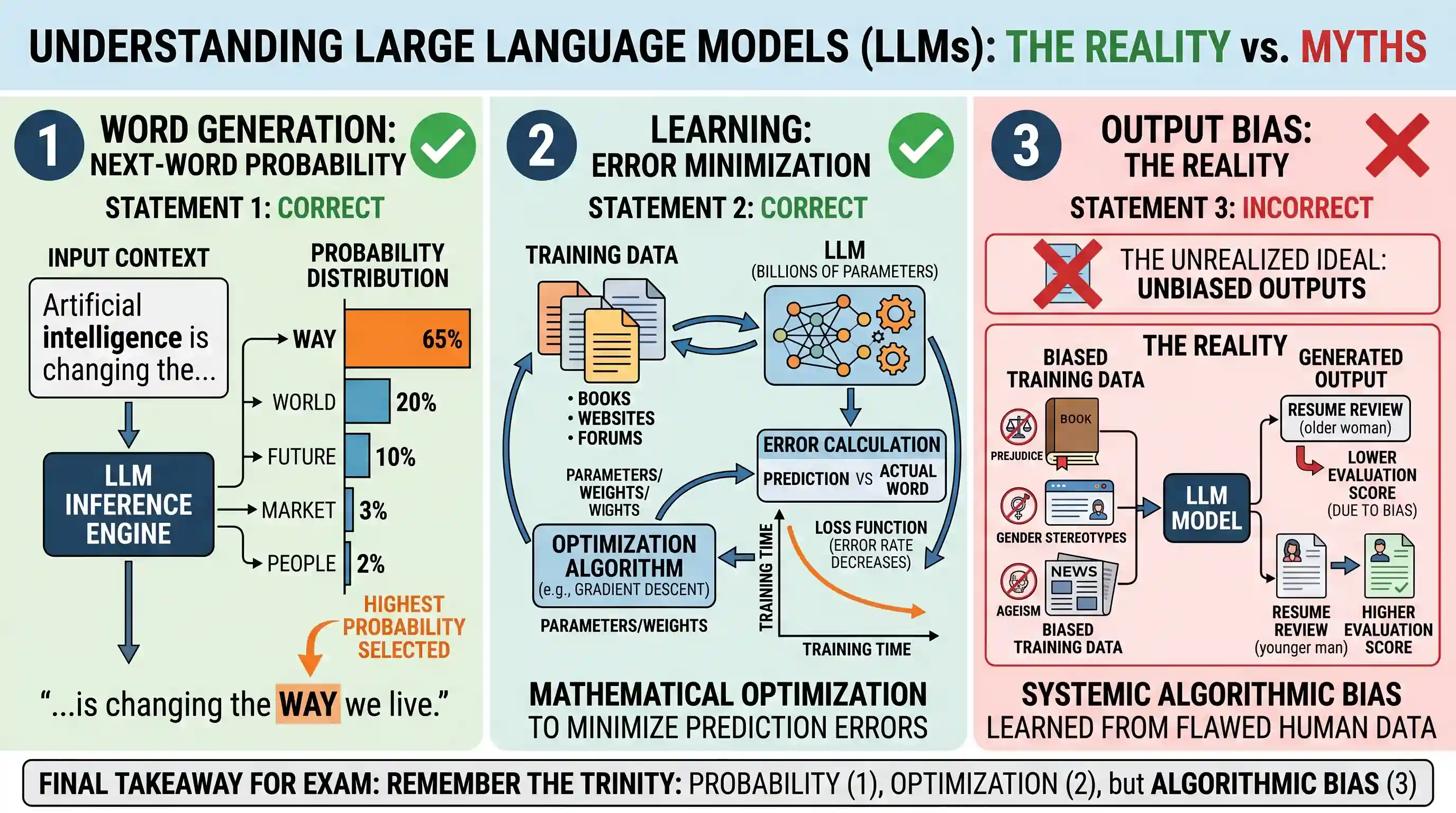
Which of the following statements with regard to Large Language Models (LLMs) used in machine learning is/are correct ? 1. LLMs assign probabilities to the next possible words and then pick the one with the highest probability. 2. LLMs process data through mathematical optimization to minimise prediction errors. 3. LLMs produce unbiased outputs. Select the answer using the code given below :
- A1 only
- B1 and 2 onlyCorrect
- C2 and 3 only
- D1, 2 and 3
Explanation
Correct Answer: B (1 and 2 only)
Statement 1 is correct: Large Language Models (LLMs) function fundamentally as next-word predictors. When generating text, an LLM analyzes the input context and computes a probability distribution across its entire vocabulary. It assigns a statistical likelihood to each possible next word (or token) and typically selects the one with the highest probability using decoding strategies (like greedy decoding) to generate coherent sentences.
Statement 2 is correct: The architecture of LLMs relies heavily on mathematical optimization during the training phase. Using algorithms such as stochastic gradient descent and backpropagation, the model continuously adjusts its billions of internal parameters (weights). The primary goal of this optimization is to minimize an objective "loss function," which mathematically represents the error rate between the model's predicted word and the actual word found in the training data.
Statement 3 is incorrect: LLMs do not inherently produce unbiased outputs. Because they are trained on vast, uncurated datasets scraped from the internet (including historical texts, forums, and articles), they absorb and often amplify the human prejudices embedded in that data. For example, a 2025 study published in Nature and reviewed by Stanford University researchers demonstrated systemic algorithmic bias in LLMs, showing that AI tools consistently downgraded hypothetical resumes belonging to older women compared to men with identical qualifications.
Takeaway: Remember the core trinity of LLMs: they use Probability for generation, Optimization for learning (error minimization), but suffer from Algorithmic Bias due to flawed human training data.
Related questions
More UPSC Prelims practice from the same subject and topic.
- Prelims 2026GS1science-technology
Which of the following statements about DHRUV64 is/are correct? 1. It is the third chip fabricated under the DIR-V Programme with an overall aim to enable the creation of microprocessors for India. 2.…
- Prelims 2026GS1science-technology
'X', born in the UK, was conferred the Nobel Prize in 2025. He was a professor in an American university when this prize was announced. Identify 'X':
- Prelims 2026GS1science-technology
Which one of the following pairs of semiconductor plants in India and their locations is not correctly matched ?
- Prelims 2026GS1science-technology
Which of the following statements with regard to India's indigenous new high resolution weather model, the 'Bharat Forecast System,' is/are correct? 1. Its objective is to generate forecasts at the Pa…
- Prelims 2026GS1science-technology
Which of the following statements regarding the features of blockchain technology are correct? 1. Records stored in the database may be made visible to relevant stakeholders without risk of alteration…
- Prelims 2026GS1science-technology
Which of the following statements with regard to genetic medicine is/are correct ? 1. Genetic medicines correct/compensate for the faulty genes responsible for disease. 2. Engineered viruses and lipid…