मशीन लर्निंग में उपयोग किए जाने वाले लार्ज लैंग्वेज मॉडल्स (Large Language Models - LLMs) के संदर्भ में निम्नलिखित कथनों में से कौन-सा/से सही है/हैं? 1. LLMs अगले संभावित शब्दों को प्रायिकताएँ (probabilities) प्रदान करते हैं और फिर सबसे अधिक प्रायिकता वाले शब्द को चुनते हैं। 2. LLMs पूर्वानुमान त्रुटियों (prediction errors) को न्यूनतम करने के लिए गणितीय अनुकूलन (mathematical optimization) के माध्यम से डेटा को प्रोसेस करते हैं। 3. LLMs निष्पक्ष (unbiased) आउटपुट उत्पन्न करते हैं。 नीचे दिए गए कूट का प्रयोग कर सही उत्तर चुनिए :
- Aकेवल 1
- Bकेवल 1 और 2Correct
- Cकेवल 2 और 3
- D1, 2 और 3
Explanation
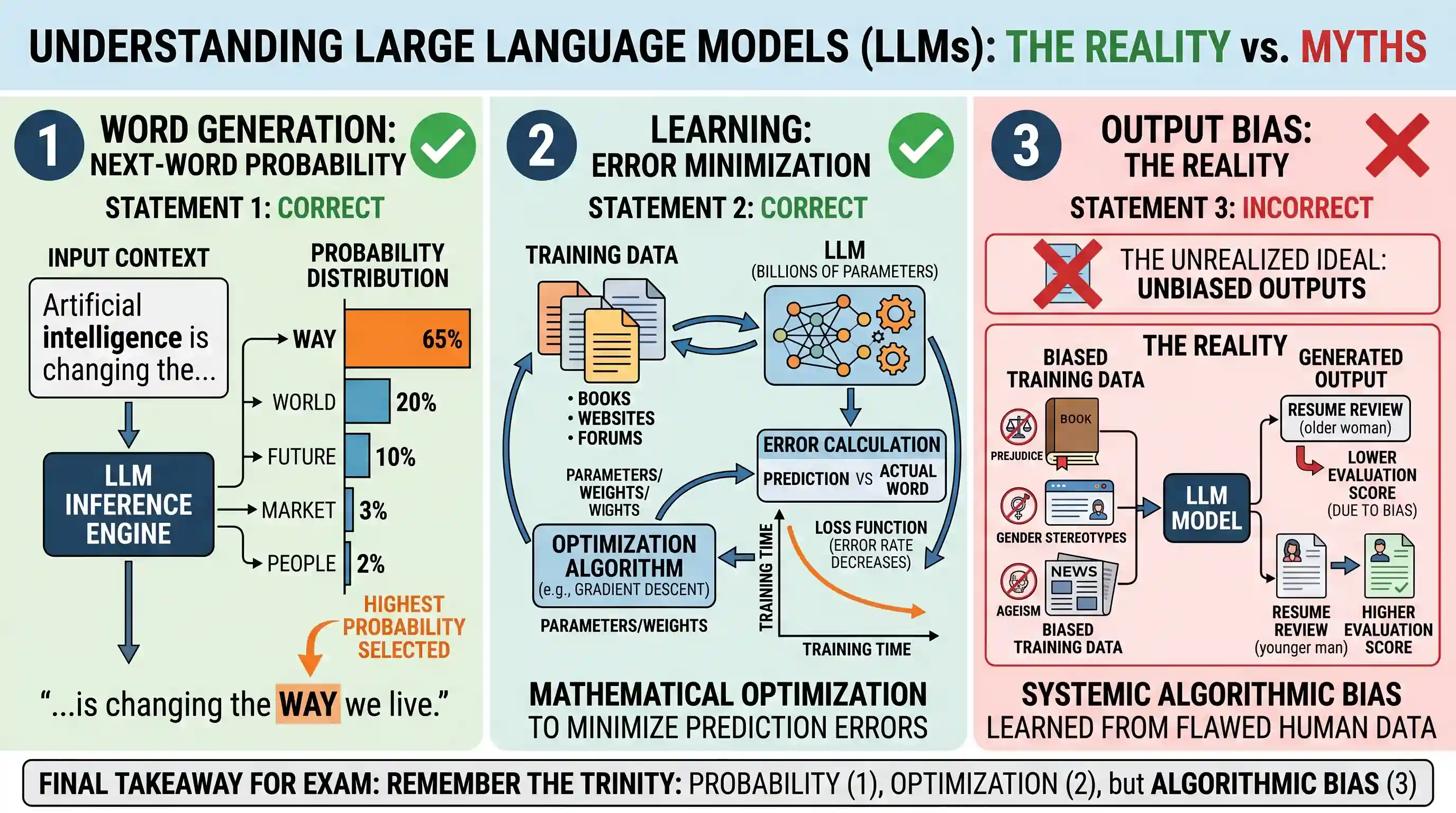
सही उत्तर विकल्प B (केवल 1 और 2) है।
लार्ज लैंग्वेज मॉडल्स (LLMs) कृत्रिम बुद्धिमत्ता (AI) और डीप लर्निंग पर आधारित तंत्रिका नेटवर्क (Neural Networks) हैं, जिन्हें विशाल मात्रा में टेक्स्ट डेटा पर प्रशिक्षित किया जाता है।
- कथन 1 सही है: LLMs मुख्य रूप से संभाव्यता (probability) आधारित इंजन के रूप में कार्य करते हैं। जब उन्हें कोई इनपुट (prompt) दिया जाता है, तो वे सांख्यिकीय पैटर्न का उपयोग करके यह गणना करते हैं कि वाक्य के क्रम में अगला संभावित शब्द (token) क्या होना चाहिए। वे विभिन्न शब्दों को प्रायिकताएँ प्रदान करते हैं और सामान्यतः सबसे अधिक प्रायिकता वाले शब्द को चुनकर वाक्य पूरा करते हैं।
- कथन 2 सही है: मॉडल के प्रशिक्षण (training) के दौरान, LLMs पूर्वानुमान त्रुटियों (prediction errors या loss) को न्यूनतम करने के लिए डेटा को प्रोसेस करते हैं। इसके लिए वे 'ग्रेडिएंट डिसेंट' (Gradient Descent) और 'बैकप्रोपेगेशन' (Backpropagation) जैसी जटिल गणितीय अनुकूलन (mathematical optimization) तकनीकों का उपयोग करते हैं, जिससे मॉडल अधिक सटीक आउटपुट दे सके।
- कथन 3 गलत है: LLMs पूर्णतः निष्पक्ष (unbiased) आउटपुट उत्पन्न नहीं करते हैं। चूँकि उन्हें इंटरनेट पर मौजूद विशाल मानव-जनित डेटासेट पर प्रशिक्षित किया जाता है, इसलिए वे अनजाने में उस डेटा में मौजूद सामाजिक, सांस्कृतिक, नस्लीय या लैंगिक पूर्वाग्रहों (biases) को भी सीख लेते हैं और अपने आउटपुट में उन्हें प्रदर्शित कर सकते हैं।
निष्कर्ष / याद रखने योग्य तथ्य: LLMs मूल रूप से 'अगले शब्द की भविष्यवाणी करने वाले सांख्यिकीय और गणितीय मॉडल' हैं। वे अनुकूलन के माध्यम से अपनी त्रुटियों को कम करते हैं, लेकिन जिस डेटा पर वे प्रशिक्षित होते हैं, उसी के पूर्वाग्रहों (biases) को भी ग्रहण कर लेते हैं।
Related questions
More UPSC Prelims practice from the same subject and topic.
- Prelims 2026CSATscience-technology
Passage: भारत में, मौसम पूर्वानुमान, पीड़क (पेस्ट) का पता लगाना और नियंत्रण, तथा फसल पैदावार का इष्टतमीकरण जैसे महत्त्वपूर्ण उपयोग के मामलों में कृत्रिम मेधा (AI) का परिनियोजन प्रारंभ किया जा रहा है। …
- Prelims 2026GS1science-technology
DHRUV64 के संदर्भ में निम्नलिखित कथनों में से कौन-सा/से सही है/हैं? 1. यह भारत के लिए माइक्रोप्रोसेसरों के निर्माण को सक्षम करने के समग्र उद्देश्य के साथ DIR-V Programme के तहत निर्मित तीसरी चिप है। 2…
- Prelims 2026GS1science-technology
भारत के स्वदेशी नए उच्च-रिज़ॉल्यूशन मौसम मॉडल, 'भारत फोरकास्ट सिस्टम' (Bharat Forecast System) के संबंध में निम्नलिखित में से कौन-सा/से कथन सही है/हैं? 1. इसका उद्देश्य पंचायत क्लस्टर स्तर पर पूर्वानु…
- Prelims 2026GS1science-technology
ब्लॉकचेन तकनीक की विशेषताओं के संदर्भ में, निम्नलिखित में से कौन-से कथन सही हैं? 1. डेटाबेस में संग्रहीत रिकॉर्ड को बिना किसी बदलाव के जोखिम के संबंधित हितधारकों के लिए दृश्यमान बनाया जा सकता है। 2. स…
- Prelims 2026GS1science-technology
आनुवंशिक चिकित्सा (genetic medicine) के संदर्भ में निम्नलिखित कथनों में से कौन-सा/से सही है/हैं? 1. आनुवंशिक चिकित्सा, बीमारी के लिए उत्तरदायी दोषपूर्ण जीन को ठीक करती है या उसकी क्षतिपूर्ति करती है। …
- Prelims 2026GS1science-technology
स्टेल्थ प्रौद्योगिकी (stealth technology) के संबंध में निम्नलिखित कथनों में से कौन-सा/से सही है/हैं? 1. स्टेल्थ वस्तुओं का रडार क्रॉस-सेक्शन बहुत छोटा होता है और उन पर रडार अवशोषक सामग्री (Radar Absor…